79769729
I can only guess as to why you are getting downvotes that it's due to the question formulation. I assume you just mean why call it a driver process when it looks like two things.
If so I think the source of your confusion is because the pyspark interface runs in a single python interpreter, this connects to a separate spark driver jvm instance - two different processes. In Databricks' classic execution this is on the same machine (it needn't be for Spark Connect). Note per #32621990 this is again different for standalone clusters.
It's also possible that you are being downvoted from not doing enough research, the terms are described here, but if so I don't think that's really fair.
Per the below diagram you referenced it looks like the user code is in the same "process", this isn't really the case for pyspark, it is for non connect Java and Scala apps run in Databricks *.
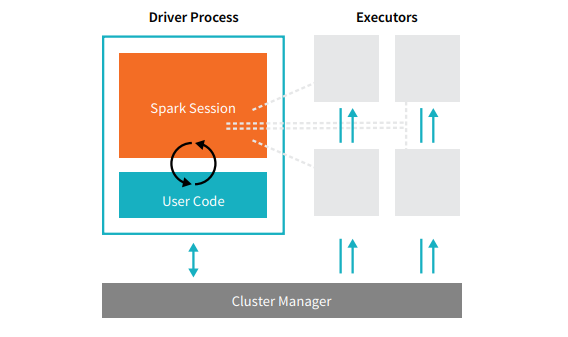
I've got really in italics as it's better to think of your python api usage as orchestrating what happens in that process box. The queries you build end up running in that user code block within the driver's jvm process, your python code is remotely starting it from another vm (or even a remote machine *).
* Note what that connection is even for classic doesn't have to be standalone e.g. master of yarn or k8s addresses. In Databricks classic you don't even provide the master, it's created for you to connect to the driver.
- RegEx Blacklisted phrase (2): downvote
- Long answer (-1):
- No code block (0.5):
- High reputation (-1):