0
Similar new issue resurfaced in 2025.
This time is due to the incompatibility with NumPy 2.x.
Simply downgrade to NumPy 1.26.x:
pip install numpy==1.26.4
or
conda install numpy==1.26.4
This will solve the Invalid property for colour.
Regards,
Hola tengo una pregunta yo estaba trabajando con visual básic 6.0 todo me iba bien..... De maravilla 👌pero resulta... Que borre un codigo del adódc y ya no hace la conexión ni se activa... Parece que es un codigo de persistencia...... Y no se que hacer...de verdad.....debe ser algún código...
Redshift cannot execute a “script” command, multiple statements in a single command. You need to run 2 command separately in the same session. This cannot be done with odbc. I’m unsure you can use a non-odbc redshift connection in vba.
If the database is set to case sensitive then all the queries against it already have this turned on. You shouldn’t need to run the first statement. Are you just trying to get the returned column names to be capitalized? There’s gotta be a simpler excel specific way to do that. If that’s the case I’d re-ask the question without mentioning redshift at all, like how do I automatically rename columns when selecting from an odbc table in vba?
check sys_query_history to find the session_id of the call to the proc, then pull all rows with that session id sorted by start_time desc. The last one is the one throwing the error. Also redshift is case sensitive and Postgres isn’t so be careful it’s not a straight port.
Apparently... Get-ItemProperty HKLM:SOFTWARE\Microsoft\SQMClient | Select -ExpandProperty MachineID returns the same value, but is there a cleaner way to get said value?
The solution ended up being a bit of a hack. I used Platypus to make a small app out of a script that calls emacsclient on the path part of the URI. The benefit of Platypus is that I was able to register the app with an emacs URI scheme handler. I updated my XSL to generate buttons that link to that URI scheme.
I was also getting the same issue the reason for that is swift is somehow saving the temporary file somewhere else and is expecting to get that file from somewhere else
error: the replacement path doesn't exist: "/var/folders/xr/s05r623x35q5112r44hjscp40000gn/T/swift-generated-sources/@__swiftmacro_8LearnFun11ContentViewV5items33_4D86A9023CAFA1CD6AABE6049862A858LL5QueryfMa_.swift"
here The expected file should be inside swift-generated-sources but xcode is saving it to one folder above that is in T folder
laziest fix: for the compiler not to compain is to create the folder swift-generated-sources and then move the file inside that folder and if the error is still there then just rename the file to match the one in the error mine was @__swiftmacro_8LearnFun11ContentViewV5items33_4D86A9023CAFA1CD6AABE6049862A858LL5QueryfMa_.swift
I managed to resolve this thanks to this quote I found on a website.
I saved this quote to my notes and implemented it, but now I can't find the original source.
Anyway, I had to remove the NSHealth stuff from the watchkit app, but keep it in the main app the watchkit extension app.
Thank you that solved my problem. I actually added this to both info.plist files for the extension and the WatchKit app. It errored out so I removed both, which was my fatal error. So again, you must have these keys in the main app and the watchkit extension app but cannot have the keys in the watchkit app.
You should be able to go to Monitor > Logs > Calls and access the audio recording of the automated verification call, without the need for the function or the Twimlet.
Can you please suggest on how to setup master and slave configuration when both master and slave machines are on Azure. The links provided talks about the steps to update remote_hosts etc., I have tried these with 2 windows Machines. Will the similar setup has to be done in Azure as well. If yes how do i do that Will there be any interface where i could login to the servers and get the installations and updates done?
Reasons:
Blacklisted phrase (0.5): Thanks
Blacklisted phrase (1): how do i
RegEx Blacklisted phrase (2.5): Can you please suggest
Were you able to resolve the issue? I had the same problem today, although I chalked it up to the number going through a WABA porting process. I also set up a backup Twilio number but I suspect some customer messages were inevitably lost in the meantime.
Reasons:
Whitelisted phrase (-1): I had the same
RegEx Blacklisted phrase (1.5): resolve the issue?
check if all tiles are loaded by comparing the total number of tiles (.leaflet-tile) with the loaded tiles (.leaflet-tile-loaded). Wait for all tiles to be fully loaded before proceeding.
Register both services. Then register a new service that has both injected into it - and this new service will check whether the feature is enabled and invoke the relevant one.
How can I gain enough "reputation" if I can't comment or ask a question? I've already been banned from asking questions because (apparently) my previous questions were all rejected for one reason or another, although most of them were asked and explained sufficiently as far as I'm concerned. It seems like you all expect an asker to guess what others may want to see.
When I got the banned notification, it said that I could "regain the right to ask a question" if I demonstrated that I could ask ask--in your minds--a valid question. But if I can't ask a question, how can I demonstrate that?
So I can't ask, I can't comment. How much sense does that make???
(base) C:\Users\admin\hu_rag>conda install -c pytorch -c nvidia faiss-gpu=1.7.4 mkl=2021 blas=1.0=mkl
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
PackagesNotFoundError: The following packages are not available from current channels:
- faiss-gpu=1.7.4
Current channels:
- https://conda.anaconda.org/pytorch/win-64
- https://conda.anaconda.org/pytorch/noarch
- https://conda.anaconda.org/nvidia/win-64
- https://conda.anaconda.org/nvidia/noarch
- https://repo.anaconda.com/pkgs/main/win-64
- https://repo.anaconda.com/pkgs/main/noarch
- https://repo.anaconda.com/pkgs/r/win-64
- https://repo.anaconda.com/pkgs/r/noarch
- https://repo.anaconda.com/pkgs/msys2/win-64
- https://repo.anaconda.com/pkgs/msys2/noarch
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
Ok, I heard back from Bridge/Zillow, and per their terms of service, no matter how many reviews there are, you can only get 10. It's semi-clear from the "documentation". Oh well.
On March 1, 2025, I confirmed that this issue is still occurring. (Windows 11 OUTLOOK_Classic). My PC also experienced a situation where Application_StartUP() would not start at all, but after making Application_Startup() and Quit() public, it started working. Even after reverting to private, it still starts normally. It might have been repaired by making only Application_Quit() public as well. In fact, I had a similar issue with Windows 7 that I had been using for a long time, where StartUP() would not start, but after changing it to public, it definitely started working. Thank you. This is a translation from Google. (From Japan)
It appears that this is a bug in the current transaction implementation in TinkerGraph. A related bug fix has recently been merged into TinkerPop but not yet released, however there appears to be a bit more going on here than what is included in that fix.
This will need more investigation to fully explain what's going on, but I can confirm now that this is an bug with TinkerGraph and not anything wrong with your usage.
I know this is a very old issue, but I was just having this issue, and searches for a solution found a lot of people asking the same question, but no solutions. Hopefully this will help someone else…
I eventually figured out that my reference to the document picker was a local variable that was going out of scope after the picker is displayed. I believe when the view is dismissed, the picker is garbage collected before the callback occurs. I added a strong reference to the picker, and no longer get that error message, and the callbacks work correctly.
I would think an exported results in json format should be able to dropped back in to postman to be opened. This might not answer the question. However, I found out that you could go back to your collections runs to see the history and it kept the results there.
Go to left nav click Collections >> Click collection top folder
On the main display pane which shows the "Overview", click the "Runs" tab.
This now will show your previously run collections results again.
Now click under "All tests", it will list all test and the results.
I am not sure since the implementation details are missing, but maybe you are loading the JSON via a useEffect hook in React and somehow save the data somewhere else inbetween? Then you would need to perform a cleanup action.
It is mentioned in the official docs that this should happen in strict mode, so the dev can find and fix bugs.
If you give further information, I can give a more educated guess. :)
from dateutil.parser import parse
date_obj1='08-02-25'
date_obj1 = parse(date_obj1)
date_obj2=date_obj1.date()
# below will in String form which is not operatable data processing
print(type(date_obj1)
# below is in date format which in operatable in data processing
print(type(date_obj2))
I had the same problem until I changed how I wrote comments in my code. Instead of using // Some thing, I started using curly braces like this: {/* Some thing */}.
This issue started happening after I upgraded to Expo SDK 52. If you're facing the same error, try updating your comments to this format and see if it helps!
Now with Copilot, you can also ask, and the answer it gives matches the chosen answer on this page (albeit I added quarto so it works in a .qmd file too).
Had struggled with this today myself, so in case anyone will have the same problem:
You need to set mediaItem property with current active MediaItem.
As option, inside your AudioHandler add this:
in constructor add:
_listenForDurationChanges
void _listenForDurationChanges() {
_player.durationStream.listen((duration) {
final index = _player.currentIndex;
final newQueue = queue.value;
if (index == null || newQueue.isEmpty) return;
final oldMediaItem = newQueue[index];
final newMediaItem = oldMediaItem.copyWith(duration: duration);
newQueue[index] = newMediaItem;
queue.add(newQueue);
mediaItem.add(newMediaItem) //without this notification will be empty;
});
}
Those versions fixed my problem.
Also I have discovered that If I use an QR Scanner application instead of device own camera with SDK-52 it still failing.
So install those versions and then scan your QR code with your device's built in camera app.Hope it will help.
My best guess is that you're unable to locate the correct user, possibly because the game property doesn't match the value you're expecting. I'd recommend adding an else statement after the if's where you're trying to find the user and logging the fact that you were unable to locate the user. This should help narrow down where it's going wrong.
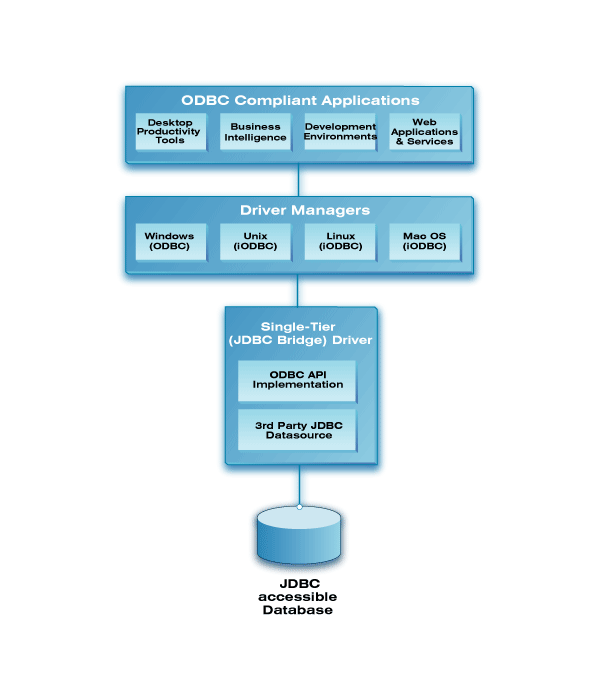
We (OpenLink Software) provide a very sophisticated ODBC-JDBC Driver that provides JDBC-accessible data sources with ODBC access from a very broad spectrum of ODBC-compliant applications and services.
These drivers exist in single-tier and multi-tier architecture forms while also being available for on a free evaluation basis -- which should help you make your final decision, cost-effectively.
As every so often, a trivial mistake: The position parameters for the origin were not converted to int, but were floating point values. I can't believe the old laptop had a resolution which never resulted in .5 floats, but applying int(...) solves the issue.
Switching to wx.GenericStaticBitmap didn't help, by the way.
Although the engineering team has an enhancement request to consider this for a future roadmap, there is currently no way to change the size constraints of a drawn signature. The alternative is to use the stamped name signature and disable the ability to draw signatures.
ThirdMapped is {} that is not empty object but object,
anything not null or undefined.
You can do something you can try to solve it with:
type EmptyObject = Record<string, never>;
type NormalizeEmpty = keyof T extends never ? EmptyObject : T;