After a lot of trial & error and a lot of Grace I worked out following workaround that really works regardless of OneDrive synchronization status.
Explainer of the situation: When OneDrive for Desktop is synchronizing an Excel workbook (let's call it Data Workbook), and that workbook is trying to be accessed from another workbook (let's call it Analysis Workbook) via PowerQuery or even directly by regular pivot table (not even PowerPivot) - Excel will regularly throw out error The process cannot access the file because it is being used by another process. That happens because the import/reading mechanism wants exclusive access to the Data Workbook (even though it is reading it only). You can't do a thing about it.
Workaround: You have to "fool" the import mechanism into thinking it is not accessing another workbook. There is a good enough solution for this which can be applied and automated in most situations:
set up a simple single formula in Analysis Workbook that pulls all relevant data from Data Workbook, and then
set up import mechanism to use that as a source.
This successfully circumvents any and all issues with OneDrive. Details on the example of using regular pivot table as the data consumer in Analysis workbook:
Let's say your data workbook is My Data.xlsx, and an Excel table in that data workbook is the source of your data, and that table is named source_data. For the sake of simplicity, I'm presuming all workbooks are in the same folder.
in Analysis workbook, add a worksheet "ds_trick", and in A1 cell place formula ='My Data.xlsx'!source_data[#All] (no matter how large the source data table is, it is going to fit into this worksheet because the formula is in A1 and there cannot be more rows in Data workbook's worksheet then in the Analysis workbook worksheet so you are safe on that side)
Let's say that this data table fills columns from A to N. Change the pivot table data source to 'ds_trick'!$A:$N. Notice that you are not specifying the rows in this reference - you are referencing whole columns!
make sure that whatever automation mechanism you are creating is opening the Data workbook before you are ordering pivot cache refreshing.
Notes:
Pivot tables do not support named ranges as source so you cannot directly reference the data workbook's Excel table in it. It also won't work if you try to create a named range in analysis workbook that references table in data workbook. You have to pull the data via formula in Analysis workbook.
Without named range as data source for pivot table you are left with "fixed" number of rows to define which is not good, so the trick for that is to reference whole columns - luckly pivot tables are good with trimming empty rows so this actually is done without any latency in processing input data. This way you are successfully faking dynamic named range as source for pivot table (in terms of rows)
In a multi-sensor system, you are working to minimize the calibration error E(x, y), where x and y are
calibration parameters. The calibration error is modeled as: E(x, y) = x2 7y2 - 2xy + 3x + 4y -
15. Determine the critical points and classify them as minima or maxima. How will minimizing this calibration error improve the accuracy of your sensor readings?
The question is about identifying shared objects in Python's multiprocessing.managers.SyncManager when used by remote processes.
Simple Explanation:
When you use SyncManager in Python to manage shared objects, the objects you share (e.g., dictionaries, lists) can be used across processes, even remotely. Each shared object is assigned a unique ID or "key" when it is created.
I will just add on that I made sure targetframework was .net9.0 in all projects. It didn't build, just complained about
The current .NET SDK does not support targeting .NET 9.0. Either target .NET 6.0 or lower, or use a version of the .NET SDK that supports .NET 9.0.
Just changing base and build in the DockerFile from 6.0 to 9.0 fixed the problem. The error message wasn't even close to what the issue was.
I was able to resolve this by specifying output.type="text" to the stat_cor command. This successfully exported the negative sign as a text box, instead of an object that did not display in powerpoint.
Code below:
For anyone who has recently encountered this issue, according to this article from Microsoft System.Text.Json started supporting serialization of the derived classes since .NET7.
You can achieve this by adding attribute annotations to the main class
[JsonDerivedType(typeof(DerivedExtensionA))]
public abstract class Extension
To clear the Material-UI DatePicker input when the value is invalid, make sure to pass null to the value prop when the input doesn't meet your validation criteria. For example:
Android Gradle plugin is not the same as gradle. Use [https://docs.gradle.org/current/userguide/compatibility.html][1]. Be sure that gradle versions and Java versions match up. Update your Path and JAVA_HOME in System Environmental Variables and then restart your computer.
The problem can be solved - as CodingWithMagga has suggested - by using the rate_func option in the animate command. Here is how you can modify the command:
animations = [circle.animate(rate_func=linear, run_time=0.01).move_to(new_pos) for circle, new_pos in zip(circles, new_positions)]
from typing import AsyncGenerator, Generator
import pytest
from httpx import ASGITransport, AsyncClient
from sqlalchemy import create_engine, event, text
from sqlalchemy.exc import SQLAlchemyError
from sqlalchemy.ext.asyncio import async_sessionmaker, create_async_engine
from sqlalchemy.orm import Session, SessionTransaction
from api.config import settings
from api.database.registry import * # noqa: F403
from api.database.setup import (
async_database_url_scheme,
get_session,
sync_database_url_scheme,
)
from api.main import app
pass # Trick to load `BaseDatabaseModel` the last, since all database models must be imported before base model.
from api.database.models import BaseDatabaseModel # noqa: E402
@pytest.fixture
def anyio_backend() -> str:
return "asyncio"
@pytest.fixture
async def ac() -> AsyncGenerator:
transport = ASGITransport(app=app, raise_app_exceptions=False)
async with AsyncClient(transport=transport, base_url="https://test") as c:
yield c
@pytest.fixture(scope="session")
def setup_db() -> Generator:
engine = create_engine(
sync_database_url_scheme.format(
settings.DATABASE_USERNAME,
settings.DATABASE_PASSWORD,
settings.DATABASE_HOST,
settings.DATABASE_PORT,
"",
)
)
conn = engine.connect()
# Terminate transaction
conn.execute(text("commit"))
try:
conn.execute(text("drop database test"))
except SQLAlchemyError:
pass
finally:
conn.close()
conn = engine.connect()
# Terminate transaction
conn.execute(text("commit"))
conn.execute(text("create database test"))
conn.close()
yield
conn = engine.connect()
# Terminate transaction
conn.execute(text("commit"))
try:
conn.execute(text("drop database test"))
except SQLAlchemyError:
pass
conn.close()
engine.dispose()
@pytest.fixture(scope="session", autouse=True)
def setup_test_db(setup_db: Generator) -> Generator:
engine = create_engine(
sync_database_url_scheme.format(
settings.DATABASE_USERNAME,
settings.DATABASE_PASSWORD,
settings.DATABASE_HOST,
settings.DATABASE_PORT,
"test",
)
)
with engine.begin():
BaseDatabaseModel.metadata.drop_all(engine)
BaseDatabaseModel.metadata.create_all(engine)
yield
BaseDatabaseModel.metadata.drop_all(engine)
engine.dispose()
@pytest.fixture
async def session() -> AsyncGenerator:
# https://github.com/sqlalchemy/sqlalchemy/issues/5811#issuecomment-756269881
async_engine = create_async_engine(
async_database_url_scheme.format(
settings.DATABASE_USERNAME,
settings.DATABASE_PASSWORD,
settings.DATABASE_HOST,
settings.DATABASE_PORT,
"test",
)
)
async with async_engine.connect() as conn:
await conn.begin()
await conn.begin_nested()
AsyncSessionLocal = async_sessionmaker(
autocommit=False,
autoflush=False,
expire_on_commit=False,
bind=conn,
future=True,
)
async_session = AsyncSessionLocal()
@event.listens_for(async_session.sync_session, "after_transaction_end")
def end_savepoint(session: Session, transaction: SessionTransaction) -> None:
if conn.closed:
return
if not conn.in_nested_transaction():
if conn.sync_connection:
conn.sync_connection.begin_nested()
def test_get_session() -> Generator:
try:
yield AsyncSessionLocal
except SQLAlchemyError:
pass
app.dependency_overrides[get_session] = test_get_session
yield async_session
await async_session.close()
await conn.rollback()
await async_engine.dispose()
Let me explain the piece of code that I have written:
First of all, we need to import all models before BaseMetadata. This is what from api.database.registry import * does; in this file I have imported all models.
ac is a asynchronous httpx client.
Using setup_db fixture, in each test session we make sure we create a fresh testing database and drop it afterwards. setup_test_db creates all tables, enums, constraints, etc. based on given metadata class and drops all of them after testing.
Last and the most important part is session fixture. This fixture joins all transactions in a single test and rollbacks all of them. This way you don't need to worry if have even committed some changes to database. In addition to what I said, also we get the original database session dependency and change it to what we have created using dependency overrides.
If you need more detail about what I have done, please let me know.
Reasons:
RegEx Blacklisted phrase (2.5): please let me know
I had the same issue (changes to html not reflected when running project in Visual Studio debugger). Although the IIS server was running, the computer was not connected to the internet. After connecting to the internet, the updates were available.
Some of us CANT use jquery... ie like Defense Contractors... and using a package is not the answer to a problem that should be known in the language itself.
After a lot of trial & error and a lot of Grace I worked out following workaround that really works regardless of OneDrive synchronization status.
Explainer of the situation:
When OneDrive for Desktop is synchronizing an Excel workbook (let's call it Data Workbook), and that workbook is trying to be accessed from another workbook (let's call it Analysis Workbook) via PowerQuery or even directly by regular pivot table (not even PowerPivot) - Excel will regularly throw out error The process cannot access the file because it is being used by another process. That happens because the import/reading mechanism wants exclusive access to the Data Workbook (even though it is reading it only). You can't do a thing about it.
Workaround:
You have to "fool" the import mechanism into thinking it is not accessing another workbook. There is a good enough solution for this which can be applied and automated in most situations:
set up a simple single formula in Analysis Workbook that pulls
all relevant data from Data Workbook, and then
set up import mechanism to use that as a source.
This successfully circumvents any and all issues with OneDrive.
Details on the example of using regular pivot table as the data consumer in Analysis workbook:
Let's say your data workbook is My Data.xlsx, and an Excel table in that data workbook is the source of your data, and that table is named source_data. For the sake of simplicity, I'm presuming all workbooks are in the same folder.
in Analysis workbook, add a worksheet "ds_trick", and in A1 cell place formula
='My Data.xlsx'!source_data[#All]
(no matter how large the source data table is, it is going to fit into this worksheet because the formula is in A1 and there cannot be more rows in Data workbook's worksheet then in the Analysis workbook worksheet so you are safe on that side)
Let's say that this data table fills columns from A to N. Change the pivot table data source to 'ds_trick'!$A:$N. Notice that you are not specifying the rows in this reference - you are referencing whole columns!
make sure that whatever automation mechanism you are creating is opening the Data workbook before you are ordering pivot cache refreshing.
Notes:
Pivot tables do not support named ranges as source so you cannot directly reference the data workbook's Excel table in it. It also won't work if you try to create a named range in analysis workbook that references table in data workbook. You have to pull the data via formula in Analysis workbook.
Without named range as data source for pivot table you are left with "fixed" number of rows to define which is not good, so the trick for that is to reference whole columns - luckly pivot tables are good with trimming empty rows so this actually is done without any latency in processing input data. This way you are successfully faking dynamic named range as source for pivot table (in terms of rows)
The solution I fond is to use taylor expansions for the first moment of functions of random variables. The details can be found here: vignette_taylor_series
Hello i am new to AI stuff and also going through this example of using transformer block for time series classification.
Aside from the padding issue, may i ask why it use "channels_first" rather than "channels_last" in GlobalAveragePooling2D layer?
I have a 2D data like yours and reshape it to (batch, height, width, 1). "channel_first" give me a high accuracy to 9X% but not "channel_last".
The Keras example use 1D data, using "channel_last" but also result in a poor accuracy. But according to the definition "channels_last" should be correct
everyone!
The simplest and easiest way to implement a date-time picker is by using the input element with the datetime-local type. I highly recommend trying it out. Creating a custom component or using third-party libraries can be quite complicated due to compatibility issues with the latest Angular versions.
Create a Snowflake TASK to execute the COPY INTO command and execute that task from your process. This runs the COPY INTO commands serially as needed, eliminating the concurrency issue. Per the EXECUTE TASK documentation:
Snowflake ensures only one instance of a task with a schedule is executed at a time.
If the root task is currently running (i.e. in an EXECUTING state in the TASK_HISTORY output), the EXECUTE TASK command schedules another run of the task to start immediately after the current run is completed.
If the root task is currently scheduled (i.e. in a SCHEDULED state in the TASK_HISTORY output), the scheduled run is replaced with the requested run as usual, with the current timestamp as the scheduled time. However, if the scheduled time has passed (but the task has not yet transitioned to an EXECUTING state), then the scheduled run occurs as usual. That is, the scheduled run is not replaced with the requested run.
Check the hash that you got, if its e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855 then you have a network stability issue. That hash corresponds to an empty file, you need to switch to a different network connection. This kind of thing can be caused by funky firewalls etc issues, so just find an alternative way to connect.
I know this is an old question, but I happened here and thought of another alternative. You could return the mime type of the media file, so clients interested in that could just display it. The metadata could be added as a custom response header (with a JSON value if you prefer) so that metadata aware clients could extract the relevant information for the exact image returned without a race condition or double lookup.
I upgraded my laravel 8 backend for SPA (vue.js, sanctum) to laravel 11, and post request /broadcasting/auth returns HTML response instead of json like
{ auth: "..." }
In previous version Broadcast::routes has been called from BroadcastServiceProvider, but not is it under the hood of laravel framework in ApplicationBuilder.php, and previously I've added sanctum middleware like this
Broadcast::routes(['middleware' => ['auth:sanctum']]);
panelTitle is the one which is changing color of Details, features, changelog labels in extensions panel . Let me know if this is what you looking for.
In the end, it was due to a component higher up in the web page's structure with the style height: 100vh;. For a normal page, this worked; the page was globally not scrollable, and my sidebar's div was made scrollable, as well as the main content div, which could be scrolled within as well.
However, for printing, it is important that height of content is not limited or set in a hardcoded pixels value.
TLDR: Make sure the container's height is set to height: auto; with @media print { ... }
The key conceptual difference is that localStorage only supports strings, while IndexedDB supports objects, arrays, and binary data like Uint8Array. This is critical if you’re dealing with large files (like images or PDFs) since binary data in localStorage requires Base64 encoding, which increases file size and complexity. IndexedDB avoids this by storing binary data directly.
Another big difference is that localStorage is synchronous, whereas IndexedDB is asynchronous, allowing for non-blocking storage operations. When working on the Scanbot Web SDK, we stored large image files using IndexedDB + Web Workers to offload heavy processing to a background thread, keeping the app responsive.
Why have two stores?
localStorage is simple and fine for small key-value data (like app settings), but IndexedDB is a full client-side database. It’s meant for larger, structured, and binary data, offering better performance, capacity, and indexing.
If you’re interested in working with binary data in IndexedDB or web workers, check out this guide we wrote: https://scanbot.io/techblog/storage-wars-web-edition/. (Full disclosure: I work at Scanbot SDK, but I think this approach can help others deal with large files in the browser.)
FYI at least as of December 2024 you absolutely can use the Events API to implement slash commands. You still set up the Slash Command on your Slack App via Settings -> Slash Commands. Use the events URL as the Request URL like /slack/events. If you are using bolt.js, you can listen for slash commands using app.command()
I ran the "db.system.sessions.drop()" command and restarted the server. It rebuilt the collection, and the expireAfterSeconds parameter has the correct type.
So far it seems like dropping the collection solved the problem with on bad side effects.
Easiest way to do this would be to call window.print() when the button is clicked. That will open up the print dialog and the user can save it to PDF themselves.
Configure the IAM Role used for the connection to include following policies:
AmazonRedshiftFullAccess
AmazonS3FullAccess
AmazonVPCFullAccess
AWSGlueConsoleFullAccess
AWSKeyManagementServicePowerUser
SecretsManagerReadWrite
Add VPC endpoints for the following services (with the subnet used in the GLUE connection toggled on - find this by creating a errornous connection in Glue, and you can see it there - dno if you can find it other places)
Since I've played around with this for almost the entire day, I might have toggled other stuff too, but at least I needed these settings :)
And for the life of me, I don't get why permissions in cloud providers have to be this complicated - I get they need to stay secure, but I have probably today introduced multiple vulnerabilities in my cloud setup, just playing around with stuff I had no clue about what actually did, just trying to get this connection to work.
My best answer would be to open a ticket with JetBrains. If you give them your example project, they may be able to fix this problem. I'd also make sure they don't try to merge it into IDEA-235305 (like they did with IDEA-363863), which hasn't even been looked at since 2019. They also said this was fixed in IDEA-302560, but it obviously wasn't.
(I would love to have a REAL fix for you, but I don't have enough reputation to even comment on your question. Otherwise, I'd say, "This is happening to me too!" I really want to add this testFixtures thing to my work projects, but if IntelliJ is going to barf on resolving them, that's dead in the water.)
Reasons:
RegEx Blacklisted phrase (1.5): I don't have enough reputation
well what I did, was using access 2010 - not just the run time, I held down the shift key while clicking on the .mdb file and held it down until the database was fully loadded. That got me into the Access App. From there i was able to look at the form definitions and that in turn showed me the code.
Is that what you are after??
Got the same problem and solved it few minutes ago. If your are running @ntohq/buefy-next v.0.1.4, it didnt work for me with newest Bulma version.
Downgrading the bulma to [email protected] solved the problem.
"Last publish 5 months ago" in Buefy version for Vue 3 was a tip.
Good luck!
I had the same issue following an update to Visual Studio. I saw that the .NET Runtime Optimization Service was running the background.
After it had completed and I cleaned and rebuilt my solution, the errors had gone. I think you may just have to wait for the Runtime Optimization to complete and then it should work.
in my include search, then I do not get the missing PinNamesTypes.h error.
To address your final concern, I have gotten my pico to program the ssd1306 with the u8g2 library on the Arduino IDE. I have also gotten Arduino code ported to Vs Code via the platformio extension.
PHPCypherFile provides a robust solution for encrypting large files
securely without significant memory overhead. It combines the power of
RSA for public/private key encryption and AES-256-CBC for symmetric
encryption, ensuring both performance and security.
When you use orWhere('status' , new) in this case it will check in wins where is 'new' and it will ignore all the other conditions like app_id == 730 and user_id == 5865535.
This is what I think, to solve this you may not use orWhere in this case
I've been experiencing the same error. I have made two changes to generate the docs:
Replacing relative import statements like import .MyModule.X with absolute import statements like import MyPackage.MyModule.X.
Tweaking the Sphinx-AutoAPI configuration in the file docs/conf.py: Instead of specifying the desired directories via the option autoapi_dirs = ["../source1", "../source2", "../source3"], pointing it to the packages root directory autoapi_dirs = [".."] and then specifying autoapi_ignore = ["*pattern1*", "*file2*", "*directory3*"] to exclude all problematic files/directories. _Note that the asterisks * where required to exclude the desired directories, like e.g. "directory3" to exclude all files in directory directory3/.
The second step I did because after changing the relative import statements I've been experiencing a further error described in this question.
Remark: I wanted to submit this as a comment, but I do not have enough "reputation". I hope this answer helps although I cannot explain the details.
Details
I run sphinx-build -b html . _build in a docs directory located in the root folder of my project package.
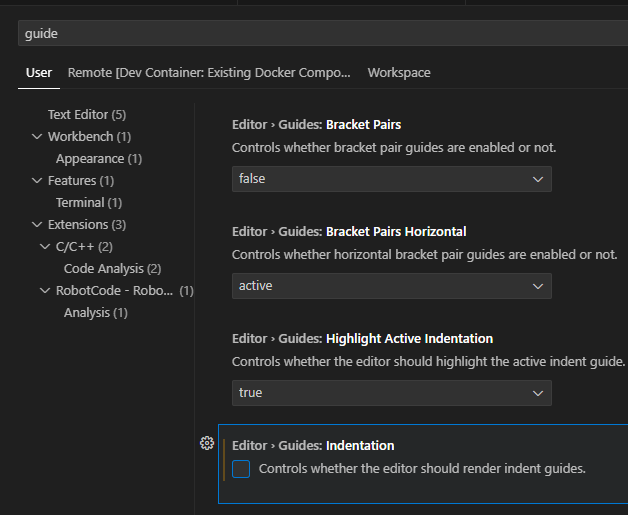
Search your settings for "guide". Uncheck the box "Editor > Guides: Indentation" and uncheck the box. See screenshot below.
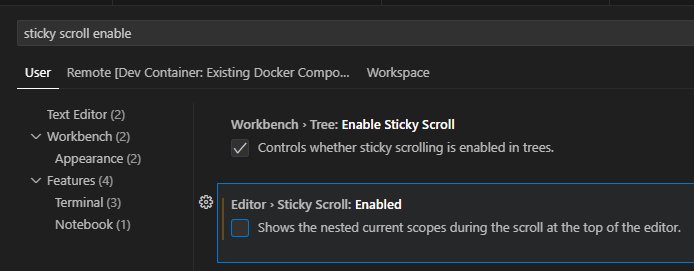
Sticky scroll
The sticky scroll feature shows what you see at the top of your screenshot. To disable that one, search your settings for "sticky scroll enable" and uncheck the checkbox. See screenshot below.
I have the same problem, the user permissions were reviewed but I still get the same error. The report executes a job from the visual studio and is executed successfully but from an application the following message does not appear:
An error has occurred during report processing. (rsProcessingAborted)
Query execution failed for dataset 'dataset1'. (rsErrorExecutingCommand)
For more information about this error navigate to the report server on the local server machine, or enable remote errors
could someone help me?
Reasons:
Blacklisted phrase (1): help me
Blacklisted phrase (1): I have the same problem
RegEx Blacklisted phrase (3): could someone help me
RegEx Blacklisted phrase (1): I still get the same error
you can't do asynchronous operation in the run.js file. If you want to check the customer tag, you can proceed from the documentation here.
With cart -> buyerIdentity -> customer -> hasAnyTag, you can check whether the tag you want exists in the user or not.
You need to use graphQL input for this. You can check the documentation here.
Actually, the encoded value seems to be a base64 encoded, and if decoded it gives what I need. What is interesting is that I don't have to use a decoder in the subsequent activities. It seems that ADF just 'shows' encoded values in the output. But if used later in a variable or another activity, it is a properly decoded value. Very unexpected, and strange.
There's currently no built in way to do that in Kedro. We've got several open issues requesting something similar (https://github.com/kedro-org/kedro/issues/2410). Feel free to comment on those, it helps with prioritisation.
I was able to install the griddb-c-client on WSL, by downloading the griddb-c-client_5.7.0_amd64.deb file from https://github.com/griddb/c_client/releases/download/v5.7.0/griddb-c-client_5.7.0_amd64.deb and saving it in my home folder, typically located on C:\USERS<login>. In my case it’s 270274. Then, I ran the following command on a WSL to install the package:
[GlobalSetup]
public void Setup()
{
_numbers = Enumerable.Range(1, 1000).ToArray();
}
[Benchmark]
public int FirstOrDefaultCondition()
{
return _numbers.FirstOrDefault(n => n == 800);
}
[Benchmark]
public int WhereFirstOrDefault()
{
return _numbers.Where(n => n == 800).FirstOrDefault();
}
}
Benchmark
So it looks like the Where(n => n ==800).FirstOrDefault() is faster than the FirstOrDefault(n => n == 800). Please see the image in benchmark.
Reasons:
Blacklisted phrase (1): enter image description here
You can try something like this to check if the value is red or not:
SELECT item.Item_ID AS ItemName,
CASE
WHEN EXISTS (SELECT 1 FROM Options optns WHERE optns.Item_ID = item.Item_ID AND optns.Color = 'Red') THEN 'Y'
ELSE 'N'
END AS IsRedOrNot FROM Items item;
After combing the documentation available up to now, I have not found any parameter, argument or method allowing to fill the Charts sections. As far as I can guess, it's not something implemented or usable yet.




{kind=link}